
|
Project Gutenberg |
 |
| Established |
1 December 1971
(First document posted)[1] |
| Collection |
| Size |
Over 40,000 documents |
| Website |
gutenberg.org |
Project Gutenberg (PG) is a
volunteer effort to
digitize and archive
cultural works, to "encourage the creation and distribution of
eBooks".[2]
It was founded in 1971 by
Michael S. Hart and is the oldest
digital library.[3]
Most of the items in its collection are the full texts of
public domain
books. The
project tries to make these as free as possible, in long-lasting,
open formats that can be used on almost any computer. As of July
2012, Project Gutenberg claimed over 40,000 items in its collection.
Wherever possible, the releases are available in
plain
text, but other formats are included, such as
HTML,
PDF, EPUB,
MOBI, and
Plucker.
Most releases are in the
English language, but many non-English works are also available.
There are multiple affiliated projects that are providing additional
content, including regional and language-specific works. Project
Gutenberg is also closely affiliated with
Distributed Proofreaders, an Internet-based community for
proofreading scanned texts.
History

Michael Hart (left) and Gregory Newby (right) of Project
Gutenberg, 2006
Project Gutenberg was started by
Michael Hart in 1971 with the digitization of the
United States Declaration of Independence.[4]
Hart, a student at the
University of Illinois, obtained access to a
Xerox Sigma V
mainframe computer in the university's Materials Research Lab.
Through friendly operators, he received an account with a virtually
unlimited amount of computer time; its value at that time has since been
variously estimated at $100,000 or $100,000,000.[4]
Hart has said he wanted to "give back" this gift by doing something that
could be considered to be of great value. His initial goal was to make
the 10,000 most consulted books available to the public at little or no
charge, and to do so by the end of the 20th century.[5]
This particular computer was one of the 15
nodes on
ARPANET,
the computer network that would become the
Internet. Hart believed that computers would one day be accessible
to the general public and decided to make works of literature available
in electronic form for free. He used a copy of the
United States Declaration of Independence in his backpack, and this
became the first Project Gutenberg
e-text.
He named the project after
Johannes Gutenberg, the fifteenth century German printer who
propelled the
movable type
printing press revolution.
By the mid-1990s, Hart was running Project Gutenberg from
Illinois Benedictine College. More volunteers had joined the effort.
All of the text was entered manually until 1989 when
image scanners and
optical character recognition software improved and became more
widely available, which made
book scanning more feasible.[6]
Hart later came to an arrangement with
Carnegie Mellon University, which agreed to administer Project
Gutenberg's finances. As the volume of e-texts increased, volunteers
began to take over the project's day-to-day operations that Hart had
run.
Starting in 2004, an improved online catalog made Project Gutenberg
content easier to browse, access and
hyperlink. Project Gutenberg is now hosted by
ibiblio
at the
University of North Carolina at Chapel Hill.
Pietro Di Miceli, an Italian volunteer, developed and administered
the first Project Gutenberg website and started the development of the
Project online Catalog. In his ten years in this role (1994–2004), the
Project web pages won a number of awards, often being featured in "best
of the Web" listings, and contributing to the project's popularity.[7]
Project Gutenberg founder, Michael Hart, died on September 6, 2011 at
his home at Urbana, IL at the age of 64.[8]
Affiliated
organizations
In 2000, a
non-profit corporation, the Project Gutenberg Literary Archive
Foundation, Inc. was chartered in
Mississippi to handle the project's legal needs. Donations to it are
tax-deductible. Long-time Project Gutenberg volunteer
Gregory Newby became the foundation's first
CEO.[9]
Charles Franks also founded
Distributed Proofreaders (DP) in 2000, which allowed the
proofreading of scanned texts to be distributed among many volunteers
over the Internet. This effort greatly increased the number and variety
of texts being added to Project Gutenberg, as well as making it easier
for new volunteers to start contributing. DP became officially
affiliated with Project Gutenberg in 2002.[10]
As of 2007, the 10,000+ DP-contributed books comprised almost a third of
the nearly 40,000 books in Project Gutenberg.
CD and DVD Project
In August 2003, Project Gutenberg created a
CD containing approximately 600 of the "best" e-books from the
collection. The CD is available for download as an
ISO
image. When users are unable to download the CD, they can request to
have a copy sent to them, free of charge.
In December 2003, a
DVD was
created containing nearly 10,000 items. At the time, this almost
represented the entire collection. In early 2004, the DVD also became
available by mail.
In July 2007, a new edition of the DVD was released containing over
17,000 books, and in April 2010, a dual-layer DVD was released,
containing nearly 30,000 items.
The majority of the DVDs, and all of the CDs mailed by the project
were recorded on recordable media by volunteers. However, the new dual
layer DVDs were manufactured, as it proved more economical than having
volunteers burn them. As of October 2010, the project has mailed
approximately 40,000 discs.[11]
Scope of
collection
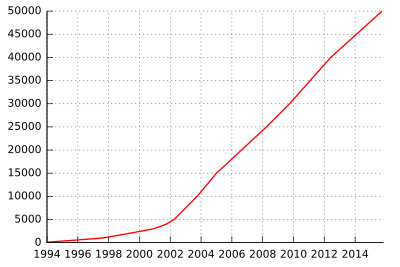
Growth of Project Gutenberg publications from 1994 until
2008.
As of November 2011, Project Gutenberg claimed over 40,000 items in
its collection, with an average of over fifty new
e-books
being added each week.[12]
These are primarily works of
literature from the
Western cultural tradition. In addition to literature such as
novels, poetry, short stories and drama, Project Gutenberg also has
cookbooks,
reference works and issues of periodicals.[13]
The Project Gutenberg collection also has a few non-text items such as
audio files and music notation files.
Most releases are in English, but there are also significant numbers
in many other languages. As of November 2010, the non-English languages
most represented are: French, German, Finnish,
Dutch, Portuguese, and Chinese.[3]
Whenever possible, Gutenberg releases are available in
plain
text, mainly using
US-ASCII
character encoding but frequently extended to
ISO-8859-1 (needed to represent accented characters in French and
Scharfes s in German, for example). Besides being copyright-free,
the requirement for a
Latin (character
set) text version of the release has been a criterion of Michael
Hart's since the founding of Project Gutenberg, as he believes this is
the format most likely to be readable in the extended future.[14]
Out of necessity, this criterion has had to be extended further for the
sizable collection of texts in East Asian languages such as Chinese and
Japanese now in the collection, where
UTF-8 is
used instead.
Other formats may be released as well when submitted by volunteers.
The most common non-ASCII format is
HTML, which
allows markup and illustrations to be included. Some project members and
users have requested more advanced formats, believing them to be much
easier to read. But some formats that are not easily editable, such as
PDF, are generally not considered to fit in with the goals of
Project Gutenberg, although many are being introduced to the collection
in
PDF format so that illustrations can be added to downloadable
documents. For years, there has been discussion of using some type of
XML, although
progress on that has been slow.[citation
needed]
Beginning in 2009 the Project Gutenberg catalog began offering
auto-generated alternate file formats, including
html, EPUB
and
plucker.[15]
Ideals
Michael Hart said in 2004, "The mission of Project Gutenberg is
simple: 'To encourage the creation and distribution of ebooks'".[2]
His goal was, "to provide as many e-books in as many formats as possible
for the entire world to read in as many languages as possible".[3]
Likewise, a project slogan is to "break down the bars of ignorance and
illiteracy",[16]
because its volunteers aim to continue spreading public
literacy and appreciation for the literary heritage just as
public libraries began to do in the late 19th century.[17][18]
Project Gutenberg is intentionally decentralized. For example, there
is no selection policy dictating what texts to add. Instead, individual
volunteers work on what they are interested in, or have available. The
Project Gutenberg collection is intended to preserve items for the long
term, so they cannot be lost by any one localized accident. In an effort
to ensure this, the entire collection is backed-up regularly and
mirrored on servers in many different locations.[citation
needed]
Copyright
Project Gutenberg is careful to verify the status of its ebooks
according to
U.S. copyright law. Material is added to the Project Gutenberg
archive only after it has received a copyright clearance, and records of
these clearances are saved for future reference. Project Gutenberg does
not claim new copyright on titles it publishes. Instead, it encourages
their free reproduction and distribution.[3]
Most books in the Project Gutenberg collection are distributed as
public domain under U.S. copyright law. The
licensing included with each ebook puts some restrictions on what
can be done with the texts (such as distributing them in modified form,
or for commercial purposes) as long as the Project Gutenberg
trademark is used. If the header is stripped and the trademark not
used, then the public domain texts can be reused without any
restrictions.[citation
needed]
There are also a few copyrighted texts that Project Gutenberg
distributes with permission. These are subject to further restrictions
as specified by the copyright holder.[citation
needed]
Criticism
The text is wrapped at 65-70 characters and paragraphs are separated
by a double-line break. Although this makes the release available to
anybody with a text-reader, a drawback of this format is the lack of
markup and the resulting relatively bland appearance.[19]
While the works in Project Gutenberg represent a valuable sample of
publications that span several centuries, there are some issues of
concern for linguistic analysis. Some content may have been modified by
the transcriber because of editorial changes or corrections (such as to
correct for obvious proof-setting or printing errors). The spelling may
also have been modified to conform with current practices (although the
intent by Project Gutenberg,[20]
and by
Distributed Proofreaders,[1]
is to preserve the original text and where possible the formatting).
This can mean that the works may be problematic when searching
for older grammatical usage. Finally, the collected works can be
weighted heavily towards certain authors (such as
Charles Dickens), while others are barely represented.[21]
In March 2004, a new initiative was begun by Michael Hart and John S.
Guagliardo[22]
to provide low-cost intellectual properties. The initial name for this
project was Project Gutenberg 2 (PG II), which created
controversy among PG volunteers because of the re-use of the project's
trademarked name for a commercial venture.[9]
Affiliated
projects
All affiliated projects are independent organizations which share the
same ideals, and have been given permission to use the Project
Gutenberg trademark. They often have a particular national, or
linguistic focus.[23]
List of
affiliated projects
-
PG-EU is a sister project which operates under the copyright law
of the
European Union. One of its aims is to include as many languages
as possible into Project Gutenberg. It operates in
Unicode to ensure that all alphabets can be represented easily
and correctly.[24]
-
Project Gutenberg Australia hosts many texts which are public
domain according to
Australian copyright law, but still under copyright (or of
uncertain status) in the United States, with a focus on Australian
writers and books about Australia.[25]
-
Project Gutenberg Canada.[26]
-
Project Gutenberg Consortia Center is an affiliate specializing
in collections of collections. These do not have the editorial
oversight or consistent formatting of the main Project Gutenberg.
Thematic collections, as well as numerous languages, are featured.[27]
-
Projekt Gutenberg-DE claims copyright for its product and limits
access to browsable web-versions of its texts.[28]
-
Project Gutenberg Europe is a project run by
Project Rastko in
Serbia.
It aims at being a Project Gutenberg for all of Europe, and started
to post its first projects in 2005. It uses the
Distributed Proofreaders software to quickly produce etexts.[29]
-
Project Gutenberg Luxembourg publishes mostly, but not
exclusively, books that are written in
Luxembourgish.[30]
-
Projekti Lönnrot, a project started by Finnish Project Gutenberg
volunteers, derives its name from the
Finnish
philologist
Elias Lönnrot (1802-1884)[31]
-
Project Gutenberg of the Philippines aims to "make as many books
available to as many people as possible, with a special focus on the
Philippines and Philippine languages".[32]
-
Project Gutenberg Russia is a project that aims to collect
public domain books in Slavic languages, Russian in particular. The
discussion of the project and its legal side began in April 2012.
The word Rutenberg is a combination of words "RUssia" and
"Gutenberg".[33]
-
Project Gutenberg Self Publishing Unlike the Gutenberg Project
itself, Project Gutenberg Self Publishing allows submission of texts
never published before, including self-published ebooks.[34]
-
Project Gutenberg of Taiwan seeks to archive copyright free
books with a special focus on Taiwan in English, Mandarin and
Taiwan-based languages. It is a special project of
Forumosa.com[35]